
이 글은 부스트코스에서 최성철님의 '인공지능(AI) 기초 다지기'를 수강 후 개인적으로 공부한 내용을 정리한 게시글입니다. 잘못된 점이나 부족한 부분이 있다면 언제든 지적 부탁드립니다.
https://www.boostcourse.org/ai100/lecture/739174?isDesc=false
인공지능(AI) 기초 다지기
부스트코스 무료 강의
www.boostcourse.org
- CSV
- 웹
- XML
- JSON
1. CSV
= Comma separate Values
: CSV, 콤마로 데이터를 나눈 텍스트 파일
: 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식이라고 생각하면 쉬움
: 탭(TSV), 빈칸(SSV) 등으로 구분해서 만들기도 함
# 엑셀로 CSV 파일 만들기
파일 → 다른 이름으로 저장 → CSV(쉼표로 분리) 선택 후 → 파일명 입력
→ 엑셀 종료 후 메모장으로 파일 열어보기
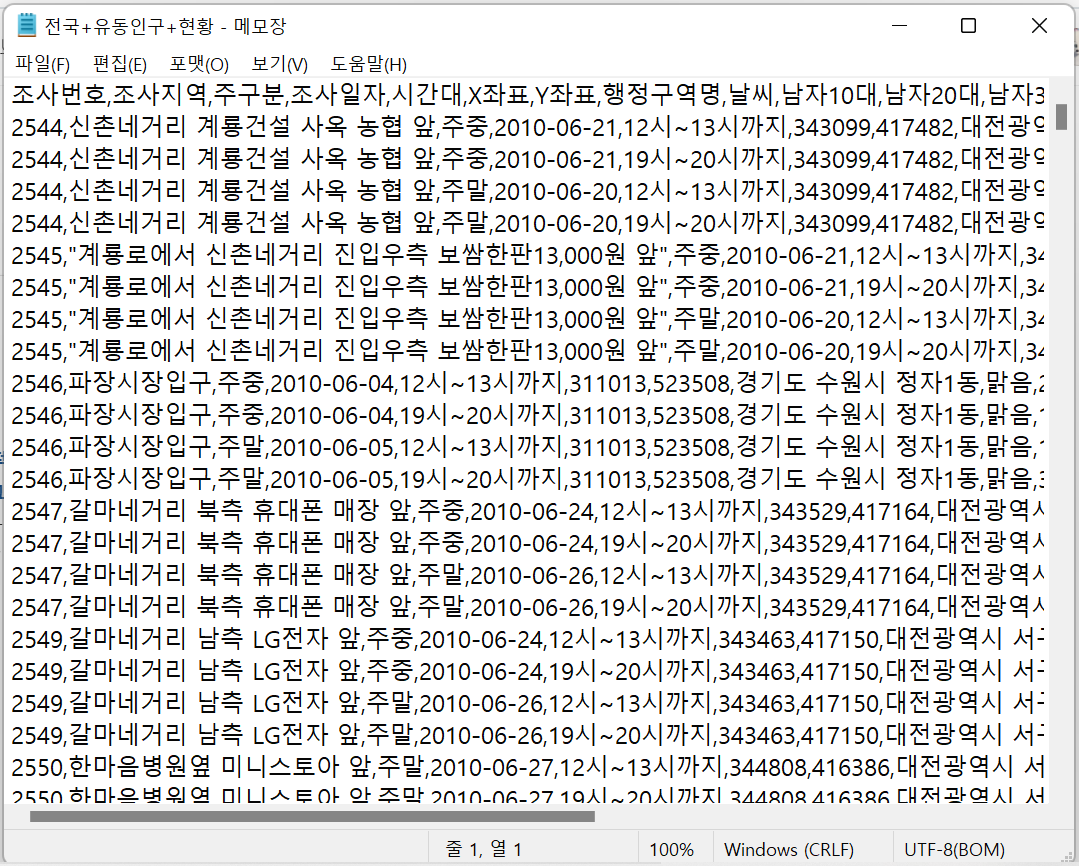
CSV는 텍스트 파일로 읽을 수 있음! 엑셀은 안됨!
* 데이터가 ","로 나누어져 있음!
# 파이썬으로 CSV 파일 읽기/쓰기
: 일반적 textfile을 처리하듯 파일을 읽어온 후, 한줄 한줄씩 데이터를 처리함
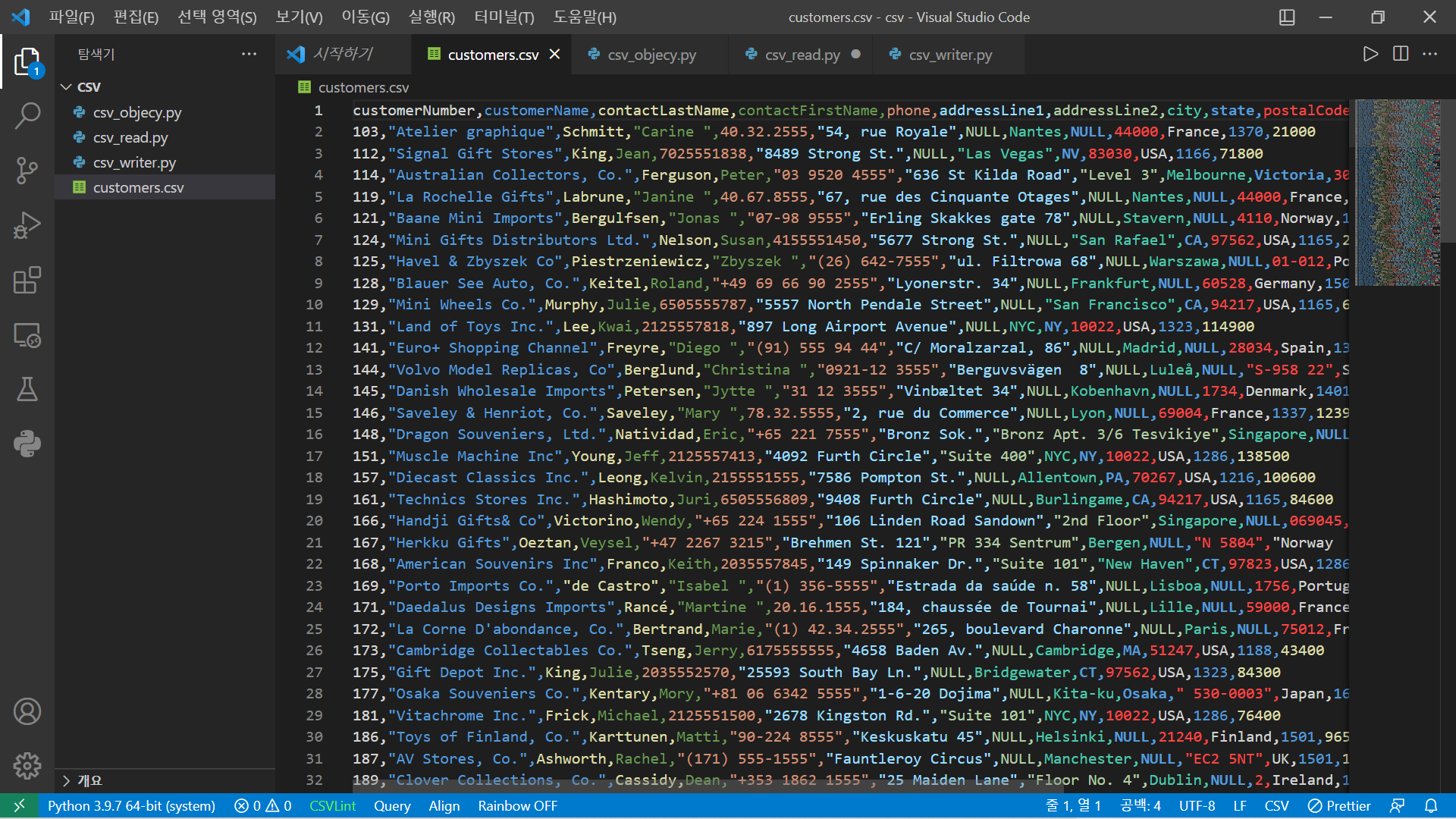
- csv_read.py
line_counter = 0 #파일의 총 줄수를 세는 변수
data_header = [] #data의 필드값을 저장하는 list
customer_list = [] #cutomer 개별 List를 저장하는 List
with open ("customers.csv") as customer_data: #customer.csv 파일을 customer_data 객체에 저장
while True:
data = customer_data.readline() #customer.csv에 한줄씩 data 변수에 저장
if not data: break #데이터가 없을 때, Loop 종료
if line_counter==0: #첫번째 데이터는 데이터의 필드
data_header = data.split(",") #데이터의 필드는 data_header List에 저장, 데이터 저장시 “,”로 분리
else:
customer_list.append(data.split(",")) #일반 데이터는 customer_list 객체에 저장, 데이터 저장시 “,”로 분리
line_counter += 1
print("Header :\t", data_header) #데이터 필드 값 출력
for i in range(0,10): #데이터 출력 (샘플 10개만)
print ("Data",i,":\t\t",customer_list[i])
print (len(customer_list)) #전체 데이터 크기 출력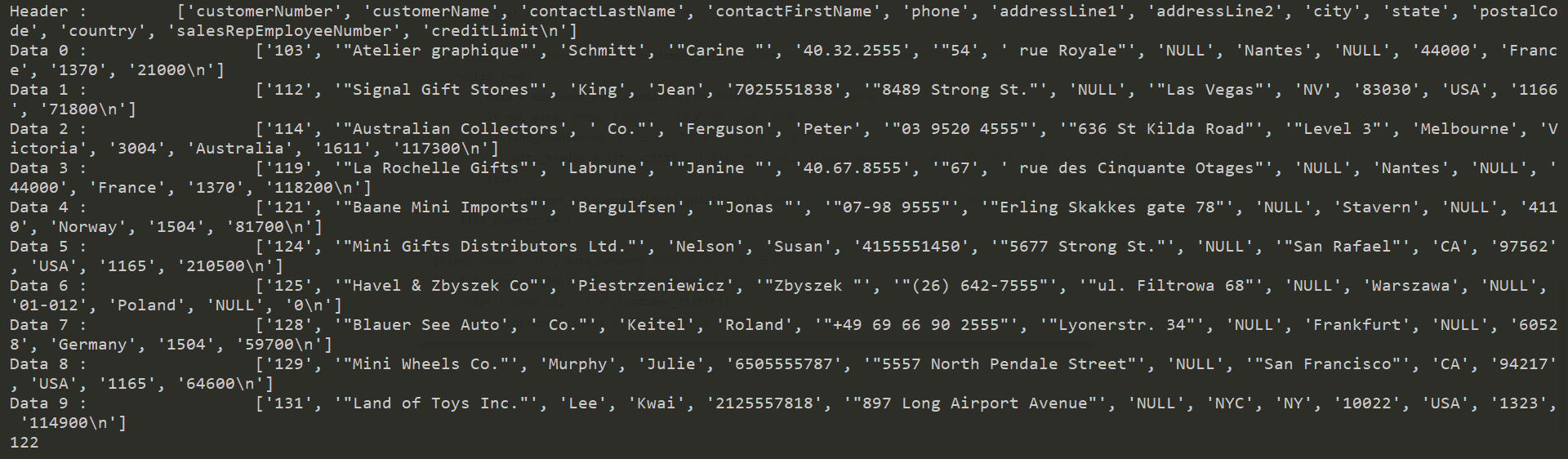
- country가 USA인것만 모아 파일 만들기
line_counter = 0
data_header = []
employee = []
customer_USA_only_list = []
customer = None
with open("customers.csv", "r") as customer_data:
while 1:
data = customer_data.readline()
if not data:
break
if line_counter == 0:
data_header = data.split(",")
else:
customer = data.split(",")
if customer[10].upper() == "USA": # customer 데이터의 offset 10번째 값
customer_USA_only_list.append(customer) # 즉 country 필드가 “USA” 것만
line_counter += 1 # sutomer_USA_only_list에 저장
print("Header :\t", data_header)
for i in range(0, 10):
print("Data :\t\t", customer_USA_only_list[i])
print(len(customer_USA_only_list))
with open("customers_USA_only.csv", "w") as customer_USA_only_csv:
for customer in customer_USA_only_list:
customer_USA_only_csv.write(",".join(customer).strip("\n") + "\n")
# cutomer_USA_only_list 객체에 있는 데이터를 customers_USA_only.csv 파일에 쓰기
# CSV 객체로 CSV 처리
: Text 파일 형태로 데이터 처리시 문장 내에 들어가 있는“,” 등에 대해 전처리 과정이 필요
: 파이썬에서는 간단히 CSV파일을 처리하기 위해 csv 객체를 제공함
: 예제데이터 : korea_foot_traffic_data.csv (from http://www.data.go.kr)
: 예제데이터는 국내 주요 상권의 유동인구 현황 정보 -한글로 되어 있어 한글 처리가 필요
-> 시간대/조사일자/행정구역/날씨 등을 기준으로 연령별/성별 유동인가 해당 지역에 몇명인가 표시
import csv
reader = csv.reader(f, # file
delimiter=',', quotechar='"',
quoting=csv.QUOTE_ALL)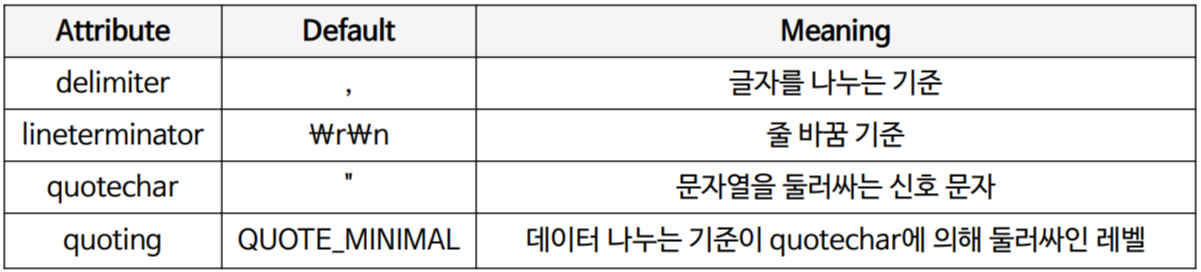
https://docs.python.org/ko/3.8/library/csv.html
csv — CSV 파일 읽기와 쓰기 — Python 3.8.12 문서
소위 CSV (Comma Separated Values – 쉼표로 구분된 값) 형식은 스프레드시트와 데이터베이스에 대한 가장 일반적인 가져오기 및 내보내기 형식입니다. CSV 형식은 RFC 4180에서 표준화된 방식으로 형식을
docs.python.org
import csv
seoung_nam_data = []
header = []
rownum = 0
with open("korea_foot_traffic_data.csv", "r", encoding="cp949") as p_file:
csv_data = csv.reader(p_file) # csv 객체를 이용해서 csv_data 읽기
for row in csv_data: # 읽어온 데이터를 한 줄씩 처리
if rownum == 0:
header = row # 첫 번째 줄은 데이터 필드로 따로 저장
location = row[7]
# “행정구역”필드 데이터 추출, 한글 처리로 유니코드 데이터를 cp949로 변환
if location.find(u"성남시") != -1: # u는 유니코드의 약자
seoung_nam_data.append(row)
# ”행정구역” 데이터에 성남시가 들어가 있으면 seoung_nam_data List에 추가
rownum += 1
with open("seoung_nam_foot_traffic_data.csv", "w", encoding="utf8") as s_p_file:
writer = csv.writer(s_p_file, delimiter="\t", quotechar="'", quoting=csv.QUOTE_ALL)
# csv.writer를 사용해서 csv 파일 만들기 delimiter 필드 구분자
# quotechar는 필드 각 데이터는 묶는 문자, quoting는 묶는 범위
writer.writerow(header) # 제목 필드 파일에 쓰기
for row in seoung_nam_data:
writer.writerow(row) # seoung_nam_data에 있는 정보 list에 쓰기
delimiter는 데이터를 자르는 기준
qoutechar는 데이터를 싸매는 기준
2. Web
HTML 분석하는 방법
- str
- RegEx
- BeautifulSoup
# 정규식 regular expression
: 복잡한 문자열 패턴을 정의하는 문자 표현 공식
: 특정한 규칙을 가지 문자열의 집합을 추출
- 텍스트만 보고 싶음!
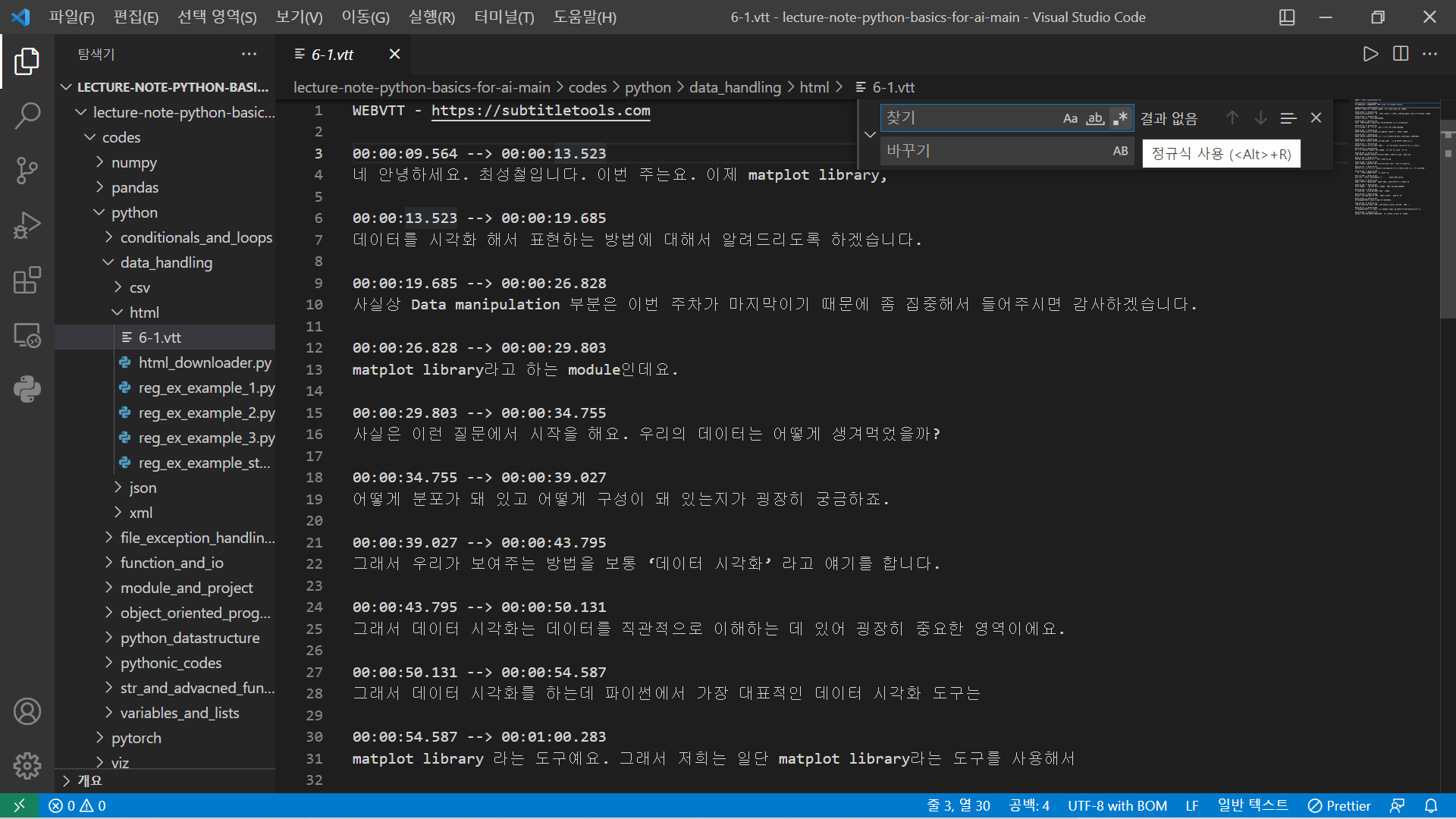
ctrl + h 누르고 정규식 입력


모두 바꾸기 클릭!
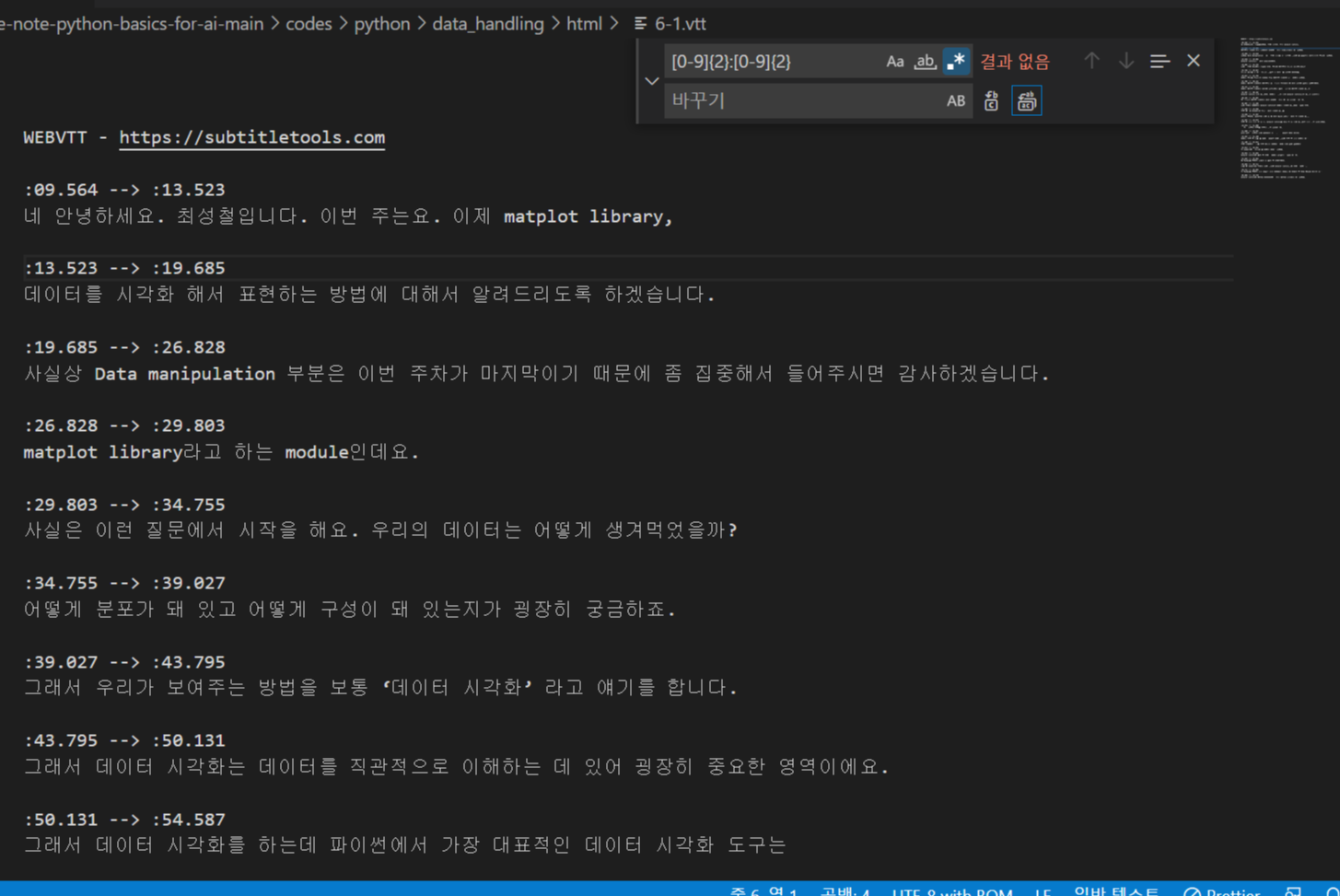
# 정규식 for HTML Parsing
: 주민등록 번호, 전화번호, 도서 ISBN 등 형식이 있는 문자열을 원본 문자열로부터 추출함
: HTML역시 tag를 사용한 일정한 형식이 존재하여 정규식으로 추출이 용이함
: 관련자료: http://www.nextree.co.kr/p4327/

!! 정규식 연습하기 http://www.regexr.com/
테스트 하고 싶은 문서를 Text 란에 삽입 -> 정규식을 사용해서 찾아보장
RegExr: Learn, Build, & Test RegEx
RegExr is an online tool to learn, build, & test Regular Expressions (RegEx / RegExp).
regexr.com
# 정규식 기본 문법
- 문자 클래스 [ ]: [ 와 ] 사이의 문자들과 매치라는 의미
예) [abc] 해당 글자가 a,b,c중 하나가 있다.
“a”, “before”, “deep” , “dud”, “sunset”
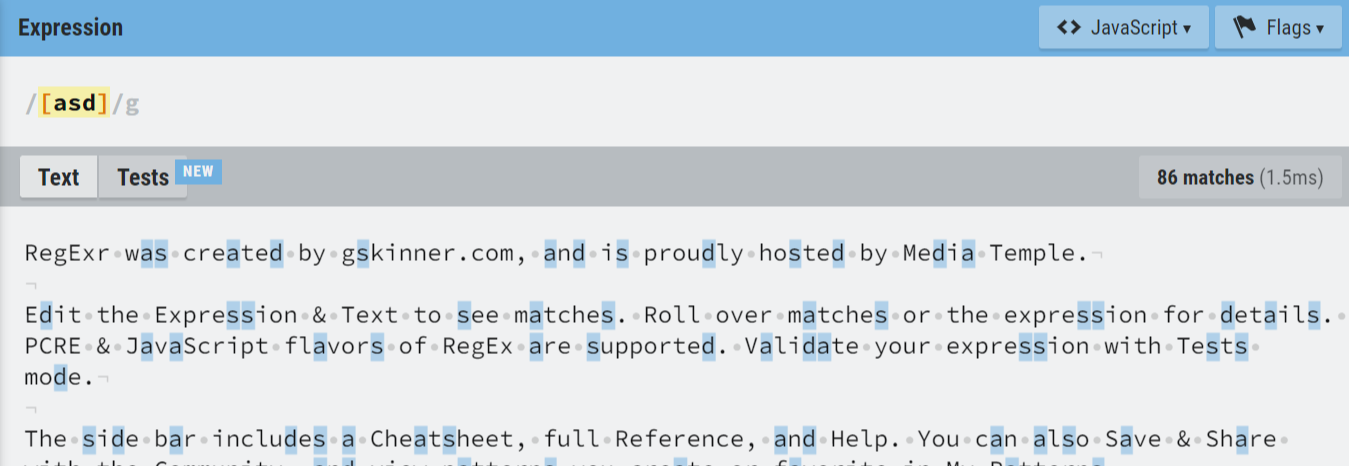
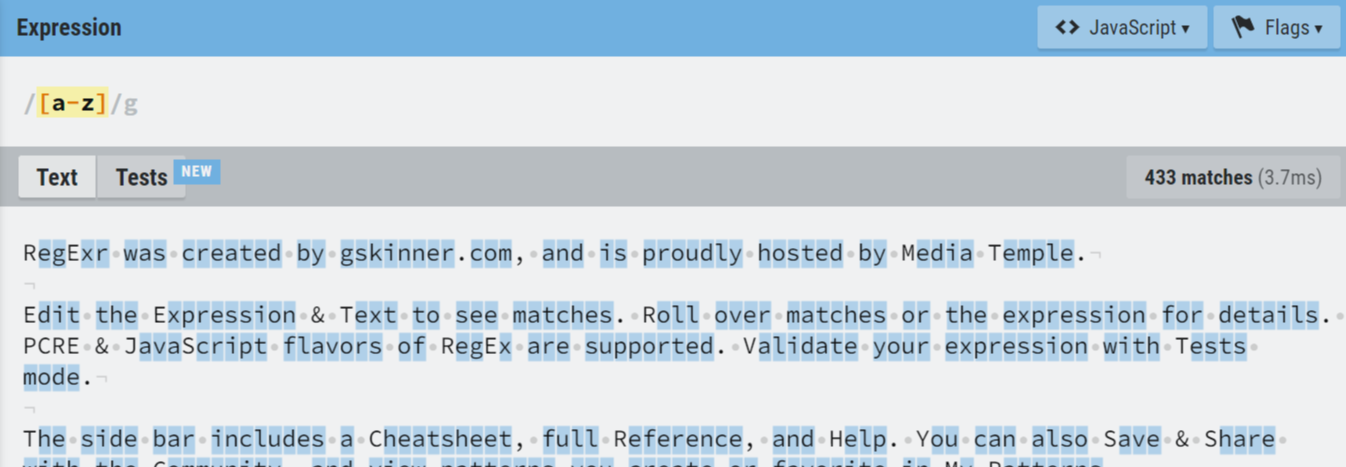
- “-“를 사용 범위를 지정할 수 있음
예) [a-zA-z] – 알파벳 전체, [0-9] – 숫자 전체
- 메타 문자
: 정규식 표현을 위해 원래 의미 X, 다른 용도로 사용되는 문자
. ^ $ * + ? { } [ ] \ | ( )


# 정규식 추출 연습
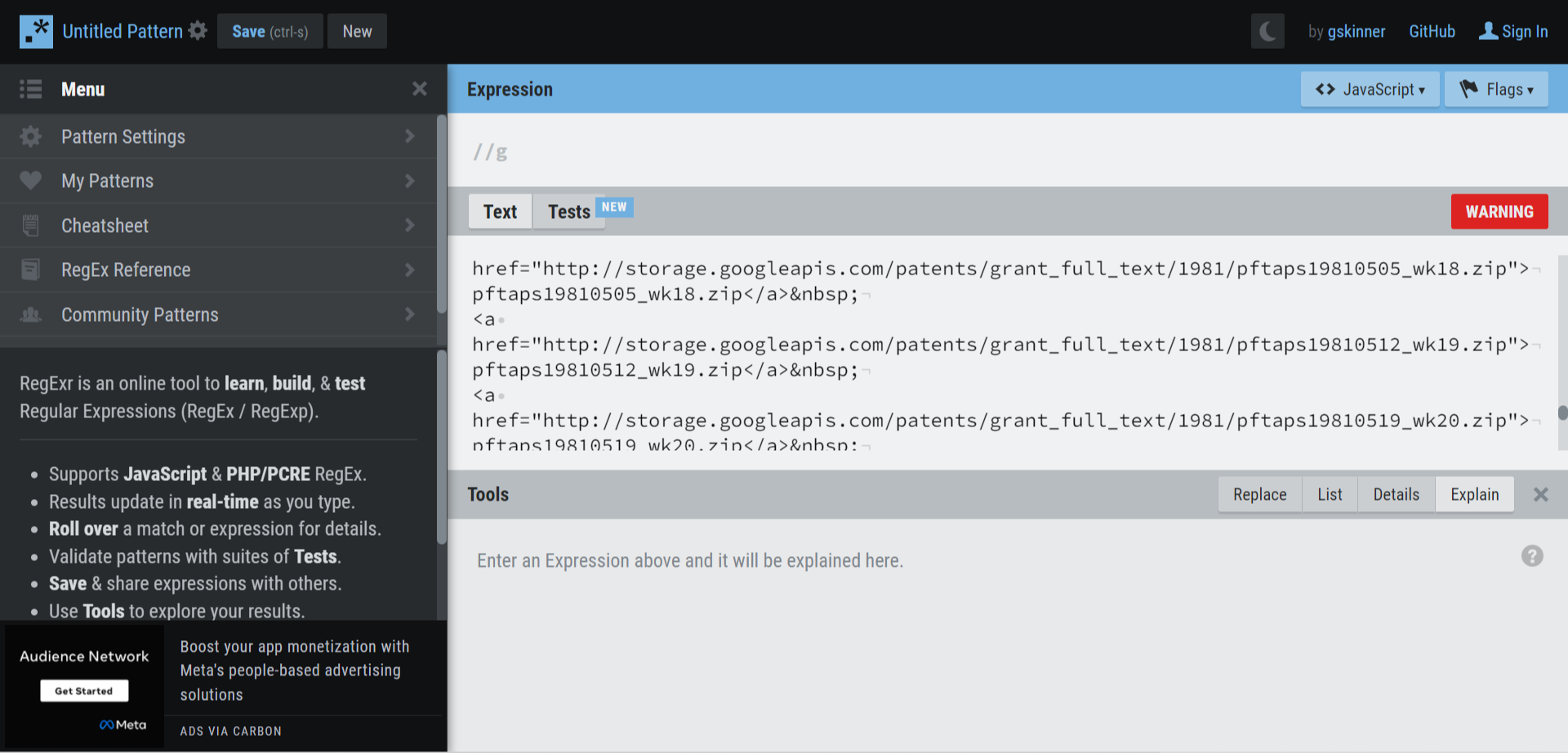
- Zip으로 끝나는 파일명만 추출하기
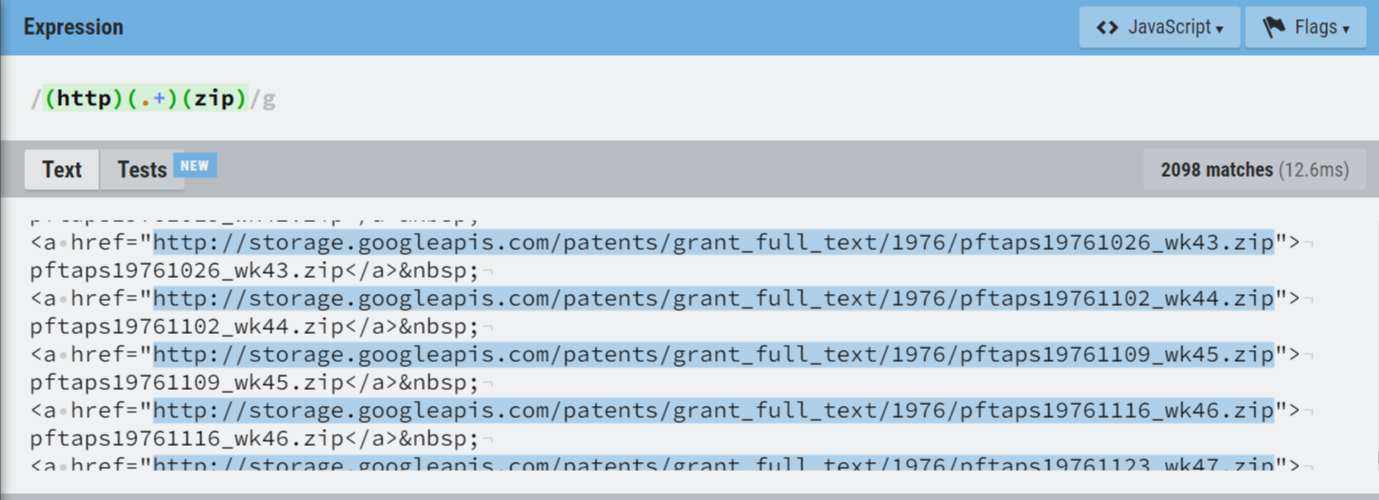
(http)(.+)(zip)
// http부터 시작하고 zip으로 끝나는데 그 사이엔 무엇이 오든 상관없음
# 정규식 in 파이썬
- re 모듈을 import 하여 사용 : import re
- search 한 개만 찾기, findall 전체 찾기
- 추출된 패턴은 tuple로 반환됨
- 연습 - 특정 페이지에서 ID만 추출하기 https://bit.ly/3rxQFS4
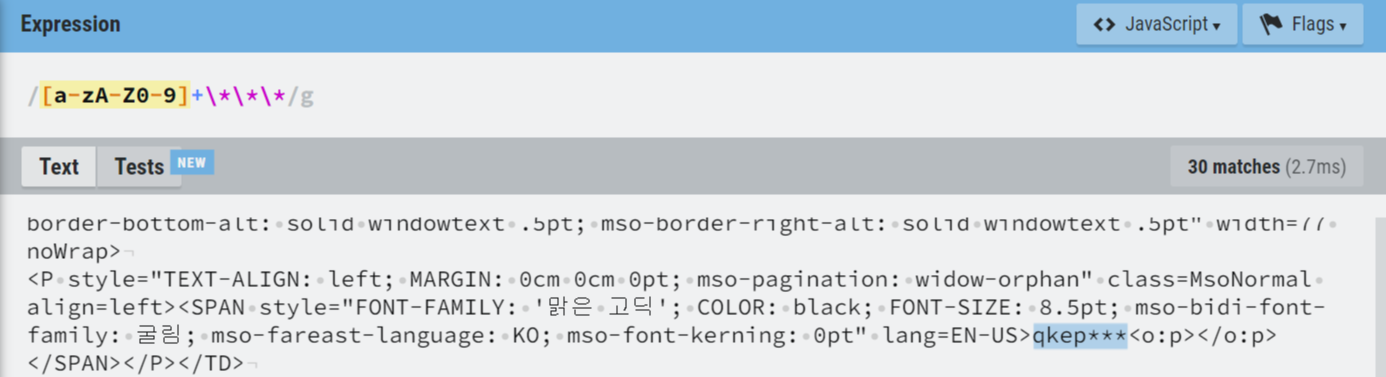
import re
import urllib.request
url = "http://goo.gl/U7mSQl"
html = urllib.request.urlopen(url) # 링크에 접속해
html_contents = str(html.read()) # contents 가져옴
id_results = re.findall(r"([A-Za-z0-9]+\*\*\*)", html_contents)
# findall 전체 찾기, 패턴대로 데이터 찾기
for result in id_results:
print(result)import urllib.request # urllib 모듈 호출
import re
url = "http://www.google.com/googlebooks/uspto-patents-grants-text.html" # url 값 입력
html = urllib.request.urlopen(url) # url 열기
html_contents = str(html.read().decode("utf8")) # html 파일 읽고, 문자열로 변환
url_list = re.findall(r"(http)(.+)(zip)", html_contents)
for url in url_list:
print("".join(url)) # 출력된 Tuple 형태 데이터 str으로 joinimport urllib.request # urllib 모듈 호출
import re
base_url = "http://web.eecs.umich.edu/~radev/coursera-slides/" # url 값 입력
html = urllib.request.urlopen(base_url) # url 열기
html_contents = str(html.read().decode("utf8")) # html 파일 읽고, 문자열로 변환
# print(html_contents )
url_list = re.findall(r"nlp[0-9a-zA-Z\_\.]*\.pdf", html_contents)
for url in url_list:
file_name = "".join(url)
full_url = base_url + file_name
print(full_url)
fname, header = urllib.request.urlretrieve(full_url, file_name)
print("End Download")
import urllib.request
import re
url = "http://finance.naver.com/item/main.nhn?code=005930"
html = urllib.request.urlopen(url)
html_contents = str(html.read().decode("ms949"))
stock_results = re.findall('(\<dl class="blind"\>)([\s\S]+?)(\<\/dl\>)', html_contents)
samsung_stock = stock_results[0] # 두 개 tuple 값중 첫번째 패턴
samsung_index = samsung_stock[1] # 세 개의 tuple 값중 두 번째 값
# 하나의 괄호가 tuple index가 됨
index_list = re.findall("(\<dd\>)([\s\S]+?)(\<\/dd\>)", samsung_index)
for index in index_list:
print(index[1]) # 세 개의 tuple 값중 두 번째 값
# XML
- 데이터의 구조와 의미를 설명하는 TAG(MarkUp)를 사용하여 표시하는 언어

- TAG와 TAG사이에 값이 표시되고, 구조적인 정보를 표현할 수 있음
- HTML과 문법이 비슷, 대표적인 데이터 저장 방식
- 정보의 구조에 대한 정보인 스키마와 DTD 등으로 정보에 대한 정보(메타정보)가 표현되며, 용도에 따라 다양한 형태로 변경가능
- XML은 컴퓨터(예: PC ↔ 스마트폰)간에 정보를 주고받기 매우 유용한 저장 방식으로 쓰이고 있음
~ 46분부터 다시
출처
부스트코스 - 최성철님 인공지능(AI) 기초 다지기
'AI > 부스트코스 인공지능 기초 1기' 카테고리의 다른 글
| 부스트 코스 AIBasic 코칭스터디 2주차 미션 피드백 정리 (0) | 2022.02.14 |
|---|---|
| 부스트 코스 AIBasic 코칭스터디 3주차 미션 피드백 정리 (0) | 2022.02.14 |
| [Python] Exception Handling / File Handling / Logging Handling (0) | 2022.01.23 |
| 부스트 코스 AIBasic 코칭스터디 1주차 미션 피드백 정리 (0) | 2022.01.19 |