
이 글은 부스트코스에서 최성철님의 '인공지능(AI) 기초 다지기'를 수강 후 개인적으로 공부한 내용을 정리한 게시글입니다. 잘못된 점이나 부족한 부분이 있다면 언제든 지적 부탁드립니다.
https://www.boostcourse.org/ai100/lecture/739173?isDesc=false
인공지능(AI) 기초 다지기
부스트코스 무료 강의
www.boostcourse.org
- Exception Handling
- File Handling
- Logging Handling
Exception Handling
1. try~except문
try:
예외 발생 가능 코드
except <Exception Type>:
예외 발생시 대응하는 코드// 0으로 숫자를 나눌 때 예외처리 하기
for i in range(10):
try:
print(10 / i)
except ZeroDivisionError:
print("Not divided by 0")# Bulit- in Exception / 빌트인 예외 처리

https://docs.python.org/3/library/exceptions.html
Built-in Exceptions — Python 3.10.2 documentation
In Python, all exceptions must be instances of a class that derives from BaseException. In a try statement with an except clause that mentions a particular class, that clause also handles any exception classes derived from that class (but not exception cla
docs.python.org
-> Exception 여러개도 가능
a = [1,2,3,4,5]
for i in range(10):
try:
print(i,10//i)
print(a[i])
print(v)
except ZeroDivisionError:
print("Not divided by 0")
except IndexError as e:
print(e)
except Exception as e: # 특별히 지정하지 않은 에러 잡아줌! -> 어디서 에러가 발생한건지 모르는 단점이 있음(좋은 코드는 아닌 듯)
print(e)2. try~except~else
try:
예외 발생 가능 코드
except <Exception Type>:
예외 발생시 동작하는 코드
else:
예외가 발생하지 않을 때 동작하는 코드3. try~except~finally
try:
예외 발생 가능 코드
except <Exception Type>:
예외 발생시 동작하는 코드
finally:
예외 발생 여부와 상관없이 실행됨4. raise 구문
raise <Exception Type>(예외정보)# 필요에 따라 강제로 Exception을 발생
while True:
value = input("변환할 정수 값을 입력해주세요")
for digit in value:
if digit not in "0123456789":
raise ValueError("숫자값을 입력하지 않으셨습니다")
print("정수값으로 변환된 숫자 -", int(value))5. Assert 구문
assert 예외조건# 특정 조건에 만족하지 않을 경우 예외 발생
def get_binary_nmubmer(decimal_number):
assert isinstance(decimal_number, int) # True / False -> False면 코드 멈춤
return bin(decimal_number)
print(get_binary_nmubmer(10))isinstance() 함수
: 자료형 비교
: 비교할 데이터와 자료형을 입력하여 일치하면 True, 아니면 False를 반환
if문 -> 로직적인 문제
try~except -> 잘못 입력했거나 데이터가 잘못된 것을 처리할 때 (ex.파일이 비어있을 때)
File Handling
# 파일의 종류

- 기본적인 파일 종류로 text 파일과 binary 파일로 나눔
- 컴퓨터는 text 파일을 처리하기 위해 binary 파일로 변환시킴 (예: pyc파일)
- 모든 text 파일도 실제는 binary 파일,
ASCII/Unicode 문자열 집합으로 저장되어 사람이 읽을 수 있음
# Python File I/O
- 파이썬은 파일 처리를 위해 "open" 키워드를 사용함
f = open("<파일이름>", "접근 모드")
f.close()
'w' : 동일한 이름의 파일이 있으면 지우고 새로 작성함
'a' : 'w'와 다르게 기존의 파일에 내용을 이어서 작성함
# 파이썬의 File Read
: 파일 오픈 -> 원하는 모드로 읽기 -> 읽은 파일로 작업하기 -> 작성 -> 파일 닫기
- read() txt 파일 안에 있는 내용을 문자열로 반환
# 상대경로 : 대상파일이 같은 폴더에 있을 경우
f = open("i_have_a_dream.txt", "r" ) # 파일이 있는 곳의 주소를 연결
contents = f.read() # 파일을 읽어 contents에 저장
print(contents)
f.close() # 파일을 닫는다- with 구문과 함께 사용하기
with open("i_have_a_dream.txt", "r") as my_file:
contents = my_file.read()
print (type(contents), contents)
# 여기서는 f 이용 X- 한줄씩 읽어 List Type으로 반환함
with open("i_have_a_dream.txt", "r") as my_file:
content_list = my_file.readlines() #파일 전체를 list로 반환
print(type(content_list)) #Type 확인
print(content_list) #리스트 값 출력- 실행 시 마다 한 줄씩 읽어오기
with open("i_have_a_dream.txt", "r") as my_file:
i = 0
while True:
line = my_file.readline()
if not line:
break
print (str(i) + " === " + line.replace("\n", "")) #한줄씩 값 출력
i = i + 1- 단어 통계 정보 산출
with open("i_have_a_dream.txt", "r") as my_file:
contents = my_file.read()
word_list = contents.split(" ")
#빈칸 기준으로 단어를 분리 리스트
line_list = contents.split("\n")
#한줄 씩 분리하여 리스트
print("Total Number of Characters :", len(contents))
print("Total Number of Words:", len(word_list))
print("Total Number of Lines :", len(line_list))❓readlines / readline / read 차이점
readlines() : 파일 내용 전체를 가져와 리스트로 반환한다.
: 각 줄은 문자열 형태로 리스트의 요소로 저장된다.
ex. 5줄짜리 파일을 readlines()로 읽으면 문자열 5개를 요소로 갖는 리스트가 반환됨
readline() : 파일의 한 줄을 가져와 문자열로 반환한다.
: 파일 포인터는 그 다음줄로 이동한다.
read() : 파일 내용 전체를 가져와 문자열로 반환한다.
: readlines()와 마찬가지로 파일 내용 전체를 읽지만, 파일 내용 전체를 하나의 문자열로 반환한다.
# 파이썬의 File Wrtie
- mode는 "w", encoding="utf8"
f = open("count_log.txt", mode='w', encoding="utf8")
for i in range(1, 11):
data = "{0}번째 줄입니다.\n".format(i)
f.write(data)
f.close()- mode "a"는 추가 모드
with open("count_log.txt", mode='a', encoding="utf8") as f:
for i in range(1, 11):
data = "{0}번째 줄입니다.\n".format(i)
f.write(data)# 파이썬의 Directory 다루기
: 텍스트 파일뿐만 아니라 디렉토리 파일도 다루어보자!
- os 모듈을 사용하여 디렉토리 다루기
import os
os.mkdir("log") # 폴더명 "log"의 폴더가 생성os — 기타 운영 체제 인터페이스 — Python 3.10.2 문서
os — 기타 운영 체제 인터페이스 소스 코드: Lib/os.py 이 모듈은 운영 체제 종속 기능을 사용하는 이식성 있는 방법을 제공합니다. 파일을 읽거나 쓰고 싶으면 open()을 보세요, 경로를 조작하려면 o
docs.python.org
- 이미 존재하는지 확인하기
# try~except문
try:
os.mkdir("studypythonstudy")
except FileExistError as e:
print("이미 있는 폴더야 ~")
os.path.exists("studypythonstudy")os.path.isfile("abd") # 파일 존재 여부 확인if not os.path.isdir("log"):
os.mkdir("log")- shutil 모듈
: 파일과 파일 모음에 대한 여러 가지 고수준 연산을 제공함
: 파일 복사와 삭제를 지원하는 함수가 제공됨
: 개별 파일에 대한 연산은 -> os 모듈
import shutil
source = "i_have_a_dream.txt"
dest = os.path.join("abc", zer0.txt") # 'abc\\zer0.txt' -> 합쳐줌(join구문), abc 폴더 밑에 zer0.txt 파일을 넣어라
# 직접 "abc" + \\ + "zer0.txt" 를 사용하는건 별로임
# 왜냐 윈도우랑 맥이랑 os에서 폴더를 구분하는 기준값이 다르기 때문임
shutil.copy(source, dest) # shutil.copy은 파일 복사 함수임shutil — 고수준 파일 연산 — Python 3.10.2 문서
shutil — 고수준 파일 연산 소스 코드: Lib/shutil.py shutil 모듈은 파일과 파일 모음에 대한 여러 가지 고수준 연산을 제공합니다. 특히, 파일 복사와 삭제를 지원하는 함수가 제공됩니다. 개별 파일
docs.python.org
-최근에는 pathlib 모듈을 사용하여 path를 객체로 다룸
>>> import pathlib
>>>
>>> cwd = pathlib.Path.cwd()
>>> cwd
WindowsPath('D:/workspace')
>>> cwd.parent
WindowsPath('D:/')
>>> list(cwd.parents)
[WindowsPath('D:/')]
>>> list(cwd.glob("*"))
[WindowsPath('D:/workspace/ai-pnpp
'), WindowsPath('D:/workspace/cs50_auto_grader'), WindowsPath('D:/workspace/data-academy'),
WindowsPath('D:/workspace/DSME-AI-SmartYard'), WindowsPath('D:/workspace/introduction_to_python_TEAMLAB_MOOC'),
- Log 파일 생성하기
import os
if not os.path.isdir("log"): # 디렉토리 있는지 확인
os.mkdir("log")
if not os.path.exists("log/count_log.txt"): # 파일 있는지 확인
f = open("log/count_log.txt", 'w', encoding="utf8")
f.write("기록이 시작됩니다\n")
f.close()
with open("log/count_log.txt", 'a', encoding="utf8") as f:
import random, datetime
for i in range(1, 11):
stamp = str(datetime.datetime.now())
value = random.random() * 1000000
log_line = stamp + "\t" + str(value) +"값이 생성되었습니다" + "\n"
f.write(log_line)
- Pickle
: 객체는 메모리에 저장 - > 인터프리터 끝나면 메모리에서 사라짐
: 파이썬의 객체를 영속화(persistence) = 저장 시키는 빌트인 객체
: 데이터, object 등 실행중 정보를 저장 -> 불러와서 사용
: 저장해야하는 정보, 계산 결과(모델) 등 활용이 많음
import pickle
f = open("list.pickle", "wb")
test = [1, 2, 3, 4, 5] # 리스트 객체
pickle.dump(test, f) # test를 dump라고 하는 f에 저장
f.close()
del test # 해도 읽을 수 있음
f = open("list.pickle", "rb") # 읽기
test_pickle = pickle.load(f)
print(test_pickle)
f.close()import pickle
class Mutltiply(object):
def __init__(self, multiplier):
self.multiplier = multiplier
def multiply(self, number):
return number * self.multiplier
muliply = Mutltiply(5) # 클래스
muliply.multiply(10)
f = open("multiply_object.pickle", "wb")
pickle.dump(muliply, f)
f.close()
del muliply
f = open("multiply_object.pickle", "rb")
multiply_pickle = pickle.load(f)
multiply_pickle.multiply(5)Logging Handling
# 로그 남기기 - Logging
: 프로그램이 실행되는 동안 일어나는 정보를 기록을 남기기
ex) 유저의 접근, 프로그램의 Exception, 특정 함수의 사용
: Console 화면에 출력, 파일에 남기기, DB에 남기기 등등
: 기록된 로그를 분석하여 의미있는 결과를 도출 할 수 있음
: 실행시점에서 남겨야 하는 기록 -> 유저를 분석하기 위함
: 개발시점에서 남겨야하는 기록 -> 에러를 사전에 잡아내기 위함
❓print vs logging
: 기록을 print로 남기는 것은 가능 -> Console 창에만 남기는 기록은 분석시 사용불가
: 레벨별(개발, 운영)로 기록을 남길 필요도 있음
: 모듈별로 별도의 logging을 남길 필요도 있음
-> 이러한 기능을 체계적으로 지원하는 모듈이 필요함!
# Logging 모듈
- Python의 기본 Log 관리 모듈
import logging
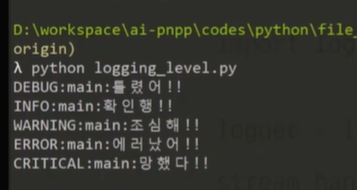
logging.debug("틀렸잖아!")
logging.info("확인해")
logging.warning("조심해!")
logging.error("에러났어!!!")
logging.critical ("망했다...") # 프로그램이 완전히 종료되었을 때# Logging Level
: 프로그램 진행 상황에 따라 다른 Level의 Log를 출력함
: 개발 시점, 운영 시점 마다 다른 Log가 남을 수 있도록 지원함
: DEBUG(개발 시점) > INFO(운영 시점) > WARNING > ERROR > Critical
: Log 관리시 가장 기본이 되는 설정 정보 **중요**

- 로그 레벨 변경
: 원래는 waring임
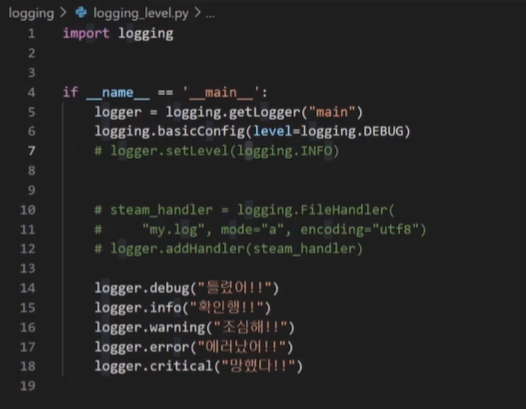
기존에는 .setLevel을 이용했으나 업데이트 이후 .basicConfig도 이용가능 하다고 한다.
steam_handler = logging.FileHandler(
"my.log", mode='w', encoding="utf8") # my.log 파일에 기록을 남기겠다
logger.addHandler(steam_handler)실제 프로그램을 실행할 때는 여러 설정이 필요하다
1. 필요한 설정 : 데이터 파일 위치, 파일 저장 장소, Operation Type 등
2. 설정해 줄 방법 : configparser - 파일에
: argparser - 실행 시점에
# configparser
: 프로그램의 실행 설정을 file에 저장함
: Section, Key, Value 값의 형태로 설정된 설정 파일 사용
: 설정 파일을 Dict Type으로 호출 후 사용
- config file
Section - 대괄호
속성 - Key : Value

- configparser file
import configparser
config = configparser.ConfigParser()
config.sections()
config.read('example.cfg') # 파일 불러옴
config.sections() # SectionOne, SectionTwo, SectionThree
print(config['SectionThree'])
for key in config['SectionOne']:
value = config[SectionOne'][key]
print("{0} : {1}".format(key,value))
config['SectionOne']["status"]# argparser
: Console 창에서 프로그램 실행시 Setting 정보를 저장함 : 거의 모든 Console 기반 Python 프로그램 기본으로 제공 :
특수 모듈도 많이 존재하지만(TF), 일반적으로 argparse를 사용
: Command-Line Option 이라고 부름
https://github.com/abseil/abseil-py
import argparse
parser = argparse.ArgumentParser(description='Sum two integers.')
parser.add_argument('-a', "--a_value", dest=”A_value", help="A integers", type=int)
parser.add_argument('-b', "--b_value", dest=”B_value", help="B integers", type=int)
# 짧은 이름, 긴 이름, 표시명, Help 설명, Argument Type
args = parser.parse_args()
print(args)
print(args.a)
print(args.b)
print(args.a + args.bdef main():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default:
64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N', help='input batch size for testing
(default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N', help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR', help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M', help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)’)
parser.add_argument('--save-model', action='store_true', default=False, help='For Saving the current Model')
args = parser.parse_args()
if __name__ == '__main__':
main()참고 >https://ddiri01.tistory.com/302
[python] argparse 구문 jupyter 에서 사용하기
argparse는 python3에 기본적으로 들어있는 pytyhon input variable 처리 라이브러리다. 사용법> def main(): # Training settings parser = argparse.ArgumentParser(description='PyTorch MNIST Example') parse..
ddiri01.tistory.com
# Logging 적용하기
- Logging formmater
: Log의 결과값의 format을 지정해줄 수 있음
formatter = logging.Formatter('%(asctime)s %(levelname)s %(process)d %(message)s')
- Log config file
logging.config.fileConfig('logging.conf') # 어떤 형태의 config를 쓸지
logger = logging.getLogger()
- Logging examples
logger.info('Open file {0}'.format("customers.csv",))
try:
with open("customers.csv", "r") as customer_data:
customer_reader = csv.reader(customer_data, delimiter=',', quotechar='"')
for customer in customer_reader:
if customer[10].upper() == "USA": #customer 데이터의 offset 10번째 값
logger.info('ID {0} added'.format(customer[0],))
customer_USA_only_list.append(customer) #즉 country 필드가 “USA” 것만
except FileNotFoundError as e:
logger.error('File NOT found {0}'.format(e,))
출처 : 부스트 코스 - 최성철 '인공지능(AI) 기초 다지기'
'AI > 부스트코스 인공지능 기초 1기' 카테고리의 다른 글
| 부스트 코스 AIBasic 코칭스터디 2주차 미션 피드백 정리 (0) | 2022.02.14 |
|---|---|
| 부스트 코스 AIBasic 코칭스터디 3주차 미션 피드백 정리 (0) | 2022.02.14 |
| [Python] Python data handling # CSV, 웹, XML, JSON (0) | 2022.01.24 |
| 부스트 코스 AIBasic 코칭스터디 1주차 미션 피드백 정리 (0) | 2022.01.19 |