
이 게시글은 인하대학교 정보통신공학과 홍성은 교수님의 인공지능 응용시스템 수업을 듣고 개인적으로 공부한 내용을 작성한 글입니다.
# Image Classification 이미지 분류
이미지 분류는 컴퓨터 비전 분야의 주요 문제이다. 사람은 고양이를 보고 고양이라고 쉽게 분류할 수 잇지만, 컴퓨터에게는 매우 어려운 문제이다. 사람은 고양이를 실체가 있는 물체로 인식하지만, 컴퓨터는 고양이를 0~255 사이의 숫자로 표현하기 때문이다.

* 문제점 : Semantic Gap
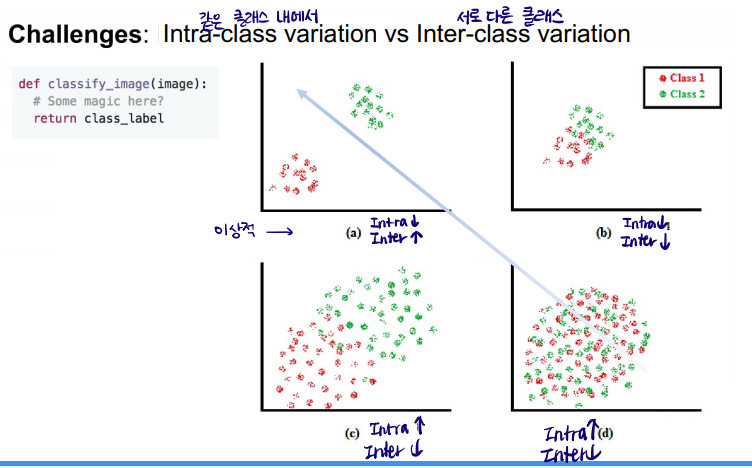
** viewpoint variation (관측 위치), Background Clutter(배경), illumination (조명). deformaion (고양이의 자세), occlusion (가림), Intra-class variation (고양이의 종류) 등에 따라 컴퓨터에게 고양이는 상당히 다르게 인식된다.
** Intra-class variation vs Inter-class variation
* Data-driven approcach 데이터 기반 방법
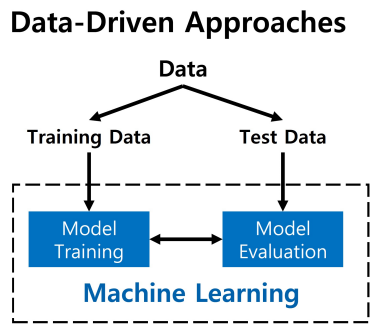
: 데이터를 기반으로 모델을 만들어 문제를 해결하고자 하는 방법이다. 데이터 기반 방법은 수많은 이미지와 레이블(ex. 고양이, 개)이 있는 데이터셋을 통해 모델을 학습(training)한다. 이 때 모델을 학습(training)하는 것을 머신 러닝이라고 한다. 이렇게 학습된 머신러닝 모델은 새로운 이미지를 input으로 받아 그 이미지의 레이블을 예측(prediction/test)한다.

: 즉, 이미지를 분류하는 모델을 만드는 방법 중 데이터 기반 방법을 머신러닝이라고 하며, 머신러닝 모델은 데이터셋을 통해 이미지를 학습하는 과정과 새로운 데이터를 예측하는 과정이 있다.
# K-최근접 이웃(K-Nearest Neighbor, KNN)
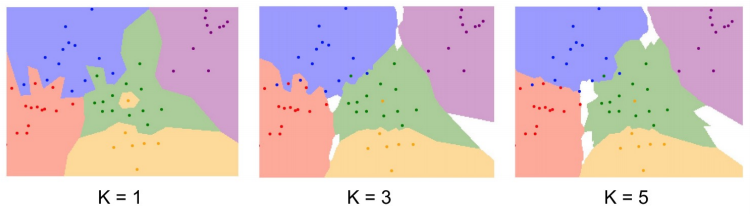
: 지도 학습 알고리즘
: 데이터가 주어지면 그 주변의 데이터를 살펴본 뒤 더 많은 데이터가 포함되어 있는 범주로 분류하는 방식
: K는 너무 작아서도 커서도 안된다. K의 default값은 5이고, 홀수여야한다. 짝수일 경우 동점이 되어 하나의 결과를 도출할 수 없기 때문이다.
: 훈련이 따로 필요없음 -> 훈련 데이터를 저장하는게 훈련의 일부
: 학습(train)은 빠르지만 테스트(predict)가 느림!
* 거리 계산
KNN에서는 데이터와 데이터 사이의 거리를 구해야하는데 두가지 방식이 있다.
- 맨해튼 거리 (Manhattan Distance)
- 유클리드 거리 (Euclidean Distance) : 점과 점 사이의 거리를 구하는 방법

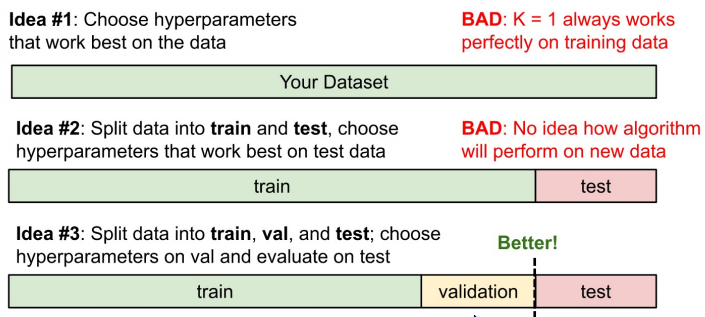
# Data Split
: Dataset을 train data와 test data로 나누는 것
Parmeter : 모델 내부에서 결정되는 변수
Hyper Parameter : 모델링할 때 사용자가 직접 세팅해주는 값
# KNN 실습 맛보기
실습 전체 내용은 코랩에 있다 ...ㅎ
# K-NN training
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
# Train the model using the fit() method with the training set 훈련
# Evaluate using the score() method with the test set 평가
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
# score() method는 0에서 1 사이의 값을 반환합니다.
# 1은 모든 데이터를 정확히 맞혔다는 것을 나타냅니다. 예를 들어 0.5라면 절반만 맞혔다는 의미입니다.
# predict() method는 새로운 데이터의 정답을 예측합니다.
kn.predict(test_input)# 샘플의 주변 샘플 알아보기
# KNeighborsClassifier 클래스는 주어진 샘플에서 가장 가까운 이웃을 찾아주는 kneighbors() method를 제공합니다.
# 이 method는 이웃까지의 거리와 이웃 샘플의 인덱스를 반환합니다.
distances, indexes = kn.kneighbors([[25, 150]])
* 두 특성(ex. 길이와 무게)의 값이 놓인 범위가 매우 다른 것을 두 특성의 스케일(scale)이 다르다고 한다.
* 샘플링 편향 Sampling Bias : 데이터 수집 시 특정 기준을 적용해서 데이터가 한 쪽으로 치우치는 현상
* Overfitting 과대 적합 : K가 너무 작을 때 -> 민감 / 학습 데이터에 대해 과하게 학습된 경우. 따라서 학습 데이터 이외의 데이터에서는 모델이 잘 동작하지 못함. 학습 데이터가 부족하거나, 데이터의 특성에 비해 모델이 너무 복잡한 경우 발생한다.
* Underfitting 과소 적합 : K가 너무 클 때 -> 둔함 / 학습 데이터도 학습을 다 하지 못한 상태. 학습 반복 횟수가 적거나 데이터 양이 적을 때 나타난다.
Overfitting과 Underfitting 정의 및 해결 방법
만약 동일한 점들이 주어지고 이 점을 대표할 수 있는 함수(곡선)을 추정하는 경우에서, 가운데가 optimize하다고 한다면 왼쪽은 지나친 단순화로 인해 에러가 많이 발생해 underfitting이라 합니다.
22-22.tistory.com
'AI' 카테고리의 다른 글
| AI 5가지 분야 Computer Vision / NLP / Speech Processing / Multimodal Learning / ML Infrastructure (0) | 2022.04.11 |
|---|---|
| 인공지능 / 머신러닝 / 딥러닝 (0) | 2022.04.11 |