
인하대학교 정보통신공학과 홍성은 교수님의 인공지능 응용시스템을 듣고 개인적으로 공부한 내용을 정리한 게시글입니다.
# Computer Vision
- Classification : 이미지가 주어졌을 때 이 이미지가 어떤 사진인지, 어떤 Object를 대표하는지 분류하는 것
- Object Detection : 객체 검출 = Classification + Localization (이미지를 입력했을 때, 그 결과가 해당 객체를 localization(bounding box)해주고, 해당 box안에 있는 객체가 무엇인지 Classification해주는 것)
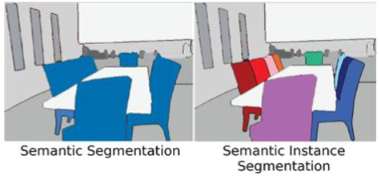
- Image Segmentation : 이미지의 영역을 분할해서 각 object에 맞게 합쳐주는 것
- GAN(Generative Adversarial Networks): 비지도 학습 / 영상을 만들어내는 알고리즘 / GAN은 두 가지 서브 모델로 구성되어 있는데, Generator 모델에서는 새로운 예제들을 생성한다. 그리고 Discriminator 모델에서는 생산된 예제가 도메인으로부터 나온 진짜 데이터인지, 아니면 Generator에서 만든 가짜 데이터인지를 판단한다.
- Image-To-Image Translation : 이미지를 입력으로 받아 또 다른 이미지를 출력으로 반환하는 태스크
- Deepfake : 인공 지능을 기반으로 한 인간 이미지 합성 기술이다. 생성적 적대 신경망(GAN)라는 기계 학습 기술을 사용하여, 기존의 사진이나 영상을 원본이 되는 사진이나 영상에 겹쳐서 만들어낸다.
# NLP (Natural Language Processing) 자연어 처리
- Machine Translation : 기계 번역 ex) 파파고
- Correction & Assistance : 오타 경고, 다음 명령어 추천
- Article Generation : AI가 쓴 기사
- Font Generation : 사람들의 손글씨를 폰트로 출시
- ANI 좁은 인공지능/ AGI 일반 인공지능 / ASI 초인공지능 : ex) GPT-3 (ANI->AGI),
- Towards Artificial General Intelligence
- Towards Artificial Super Intelligence
# Speech Processing
- Smart Speaker - Voice Assistant
- Voice Generation
- Smart Reservation
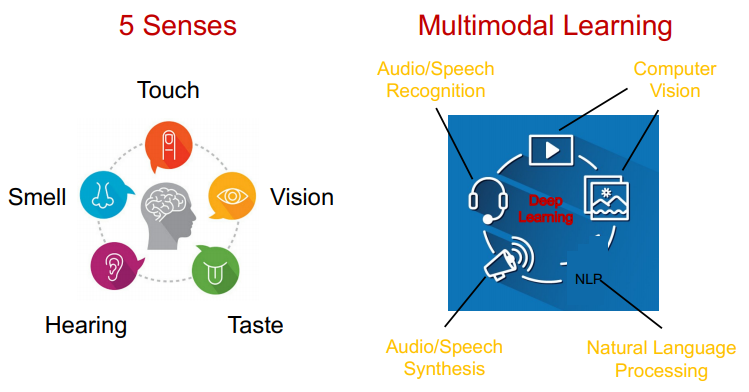
# Multimodal Learning
: 다섯가지 감각 중 두개 이상의 시그널을 조합해 추론할 수 있는 AI 분야
- Multi-Sensor Fusion
- Visual Question Answering (VQA) : input이 이미지와 이미지와 연관이 있는 질문(text)이 있다고 했을 때, AI가 적절한 대답(text)을 하는 것
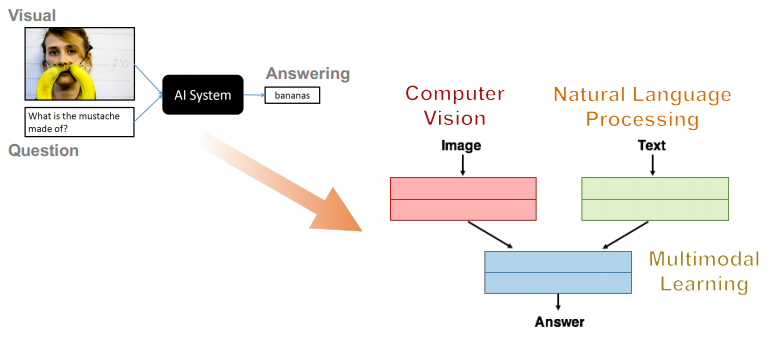
- VQA vs Captioning vs Visual Dialog : VQA는 이미지를 보고 질문에 답을 하는 것(단답형), Captioning은 이미지를 보고 이미지에 대해 나레이션 하는 것, Visual Dialog 이미지를 보고 질문과 답변을 하고, 앞서 질문한 것과 대답한 것을 기억해 대화하는 것
- Speech to Face
- Vision Meets Languages/Knowledge : GPT-3는 세상을 글로만 배운 아이이기 때문에, 영상이라는 개념을 이해하지 못한다. GPT-3에 vision기술을 접목시켜 DALL-E라고 하는 AI가 만들어졌다. 텍스트를 주면 어울리는 이미지를 만들어줌
'AI' 카테고리의 다른 글
| KNN / K-Nearest Neighbors (0) | 2022.04.12 |
|---|---|
| 인공지능 / 머신러닝 / 딥러닝 (0) | 2022.04.11 |